十亿行大数据编程挑战,如何快速统计聚合 10亿行 text 文件
-
最近逛 GitHub Trending 发现一个有意思的编程挑战项目,
项目地址 https://github.com/gunnarmorling/1brc。任务是仓库中的 measurements.txt 包含 10亿行气象站的温度数据,要求挑战者使用Java读取文件,计算每个气象站的最低、平均和最高温度值,并按气象站名称字母顺序排序后。
数据样本,如下:
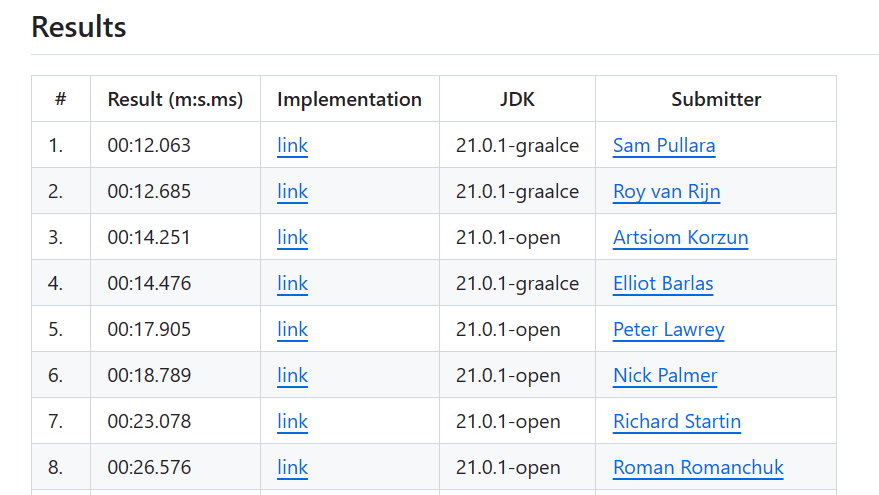
<气象站>;<double: 测量值>Hamburg;12.0 Bulawayo;8.9 Palembang;38.8 St. John's;15.2 Cracow;12.6 Bridgetown;26.9 Istanbul;6.2 Roseau;34.4 Conakry;31.2 Istanbul;23.0目前排名第一的只用了12秒时间
尝试下了,首先要安装 Java 21。
1.运行mvn clean verify构建源码,
2.执行./create_measurements.sh 1000000000,开始造数生成measurements.txt文件。好家伙跑了4分钟13个G,磁盘直接干满了。好吧,清理下垃圾腾点空间,继续。
3.测试排名第一的 calculate_average_ebarlas.sh,我的笔记本耗时11秒完成空了再分析下原理~