近年来,外面工作特别不好找。很多人希望找一些比较灵活的项目合作,来获得一些收入。听说,有不少人完全不会编程写代码,却能用AI独立开发APP,还挣了钱。于是,很多人开始跃跃欲试,将目光投向文心快码(Baidu Comate),希望用这个AI编程工具,也来找到一个收入来源。
完全不会编程,也能开发APP?只要被失业逼急了,什么事情都是愿意尝试的。只要别幻想一夜暴富,文心快码(Baidu Comate)就能成为你的“外挂”,帮你用最低成本试错,赚点零花钱。比如,做个简单工具类APP、接个小外包项目,或者把代码模板卖出去。文心快码(Baidu Comate)的核心功能Zulu是基于文心大模型专为智能编程设计的,支持多种语言。不仅能自动补全代码、智能纠错、生成文档注释,还能听懂你说话快速生成代码片段呢。不论是工程师、学生还是技术小白,用上它都能让编程变得更高效、更智能,轻松玩转代码世界!当然小白刚刚开始行动的时候,还需要从头开始摸索。
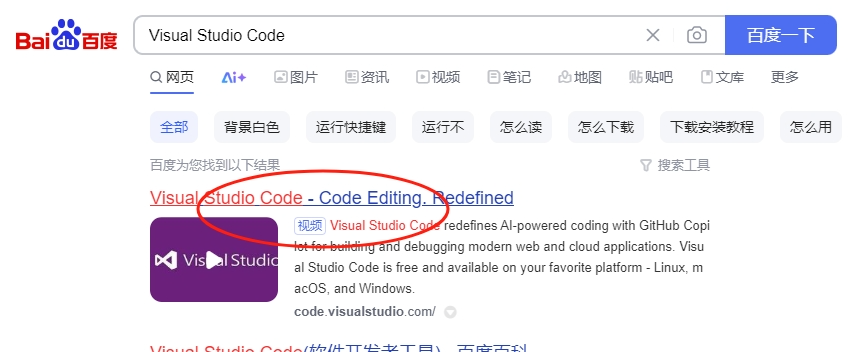
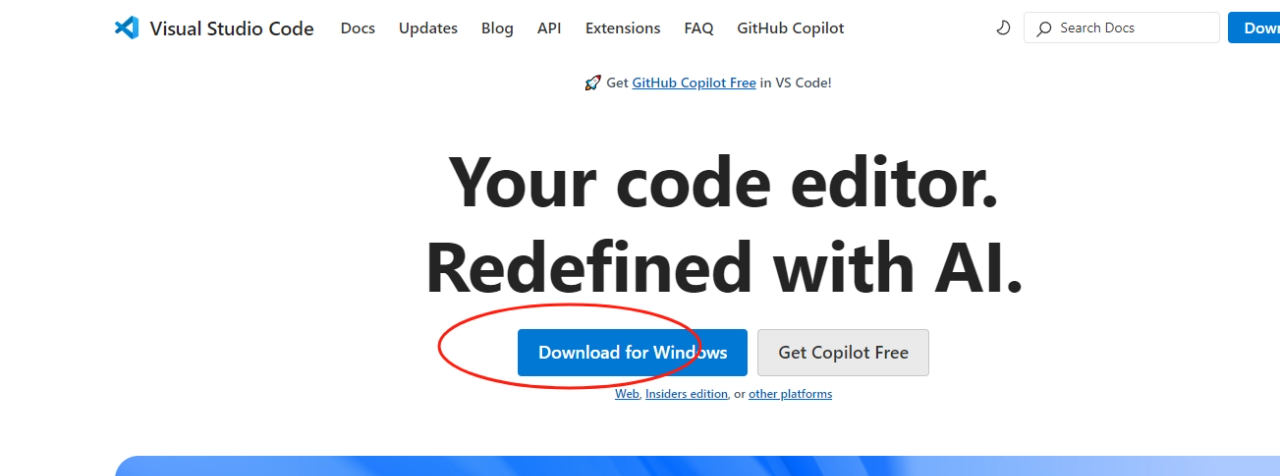
先在百度等搜索引擎中搜索"Visual Studio Code",点击官方网站链接下载适合你系统的版本,安装VS Code并启动。
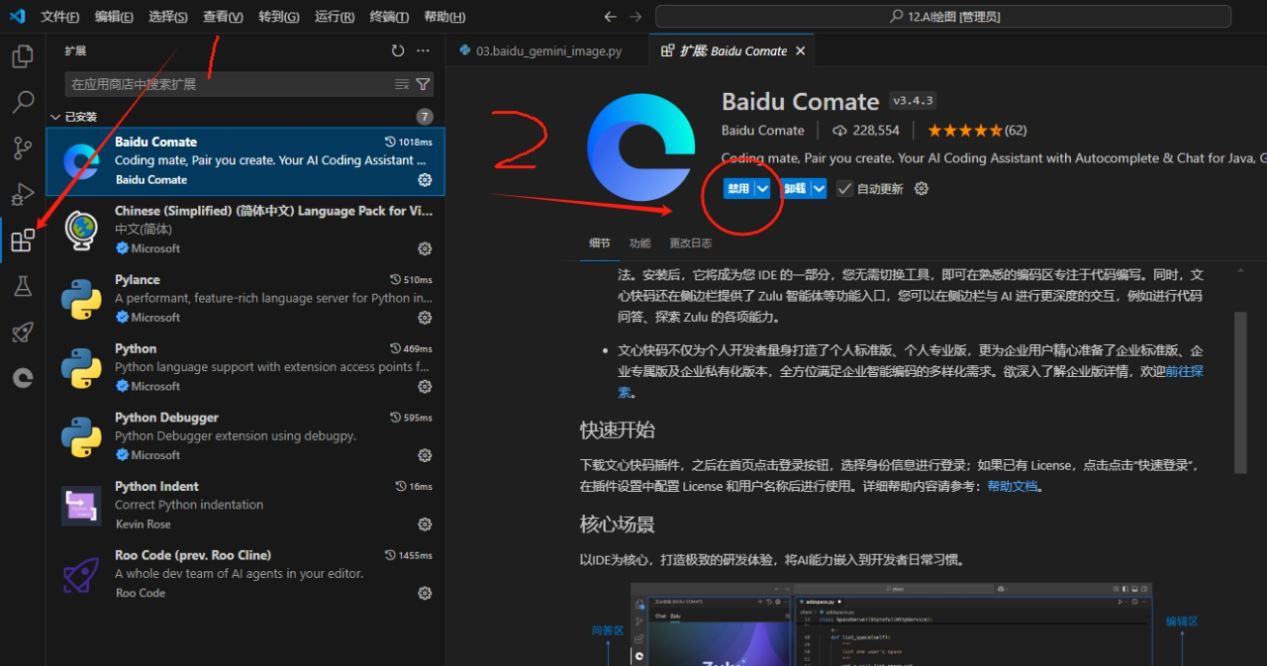
打开VS Code后,点击左侧扩展图标(或按Ctrl+Shift+X),在扩展市场搜索框中输入"Baidu Comate" 找到百度文心快码插件并点击安装。
安装完成后,在VS Code左侧边栏会出现Baidu Comate图标,点击该图标打开文心快码(Baidu Comate)面板,点击"启用"按钮激活插件,登录百度账号。
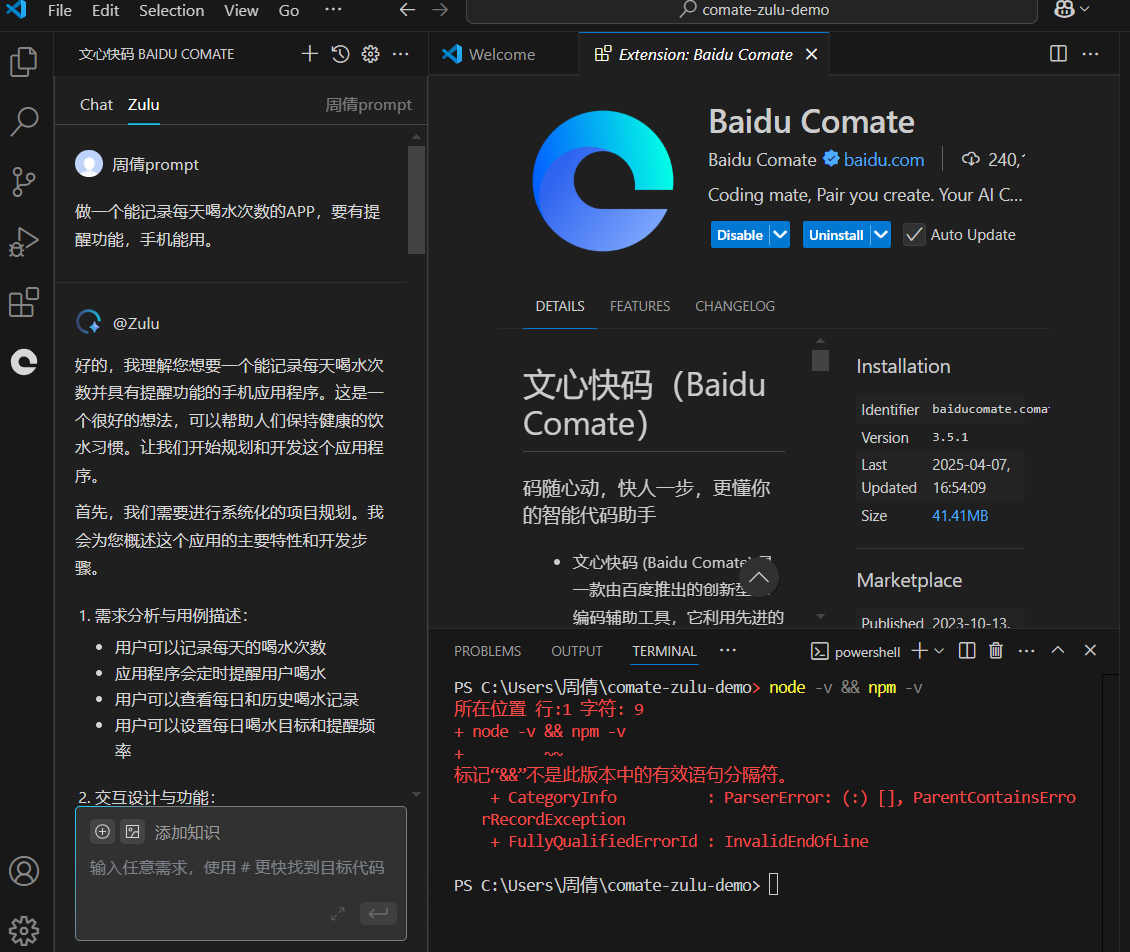
然后,就可以使用AI编程能力了。最重要是,不需要魔法就能直接使用。
文心快码(Baidu Comate)有免费额度,注册账号,在“代码补全”里输入“我想做个计算器APP”,看AI怎么生成代码。
你一定要学会提问:把需求当“点菜”一样告诉文心快码(Baidu Comate),比如:“用Python写个自动整理文件夹的脚本,要带图形界面!”
编程小白要从“微需求”入手。比如,可以考虑做一个套壳工具APP,用文心快码(Baidu Comate)生成“纪念日倒计时”“快递查询”等简单APP,上架应用商店(广告分成或付费下载)。
或者,接单平台捡漏。在猪八戒、程序员客栈等平台找“小学生作业级”需求,比如:“帮我写个Excel自动统计表格的代码”,用文心快码(Baidu Comate)生成后转手交货。
也可以卖代码模板。把文心快码(Baidu Comate)生成的通用代码(比如网页登录界面、爬虫脚本)挂到Gumroad或淘宝,标价9.9元。
据说,有人用Comate做了个“朋友圈文案生成器”网页,挂在GitHub Pages上,再挂了个打赏二维码,半年收了2000+的奶茶钱。
用文心快码(Baidu Comate)赚钱的本质是:你负责发现需求,AI负责搬砖。哪怕只会Ctrl+C/V,只要肯折腾,赚个零花钱也不是很难。