如何读取json格式的内容,报错TypeError
-
找到了动态网页的内容,如何提取json字典表里面所需的内容?
import re import json import requests headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,2): param = { 'cb': 'jQuery112408933494064226006_1636169759698', 'pn': f'{i}', 'pz': '20', 'po': '1', 'np': '1', 'ut': 'bd1d9ddb04089700cf9c27f6f7426281', 'fltt': '2', 'invt': '2', 'fid': 'f3', 'fs': 'm:0 t:80', 'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://90.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) #r=str(r) print(r.text) obj=re.search(r"data:(.*)",r.text) content=obj.group().replace("data:", "") print(content) # json_str = json.dumps(param) # print("JSON 对象:", json_str)代码报错说TypeError
跟着别人视频写的代码,人家都没报错,不知道我这是哪里出毛病了?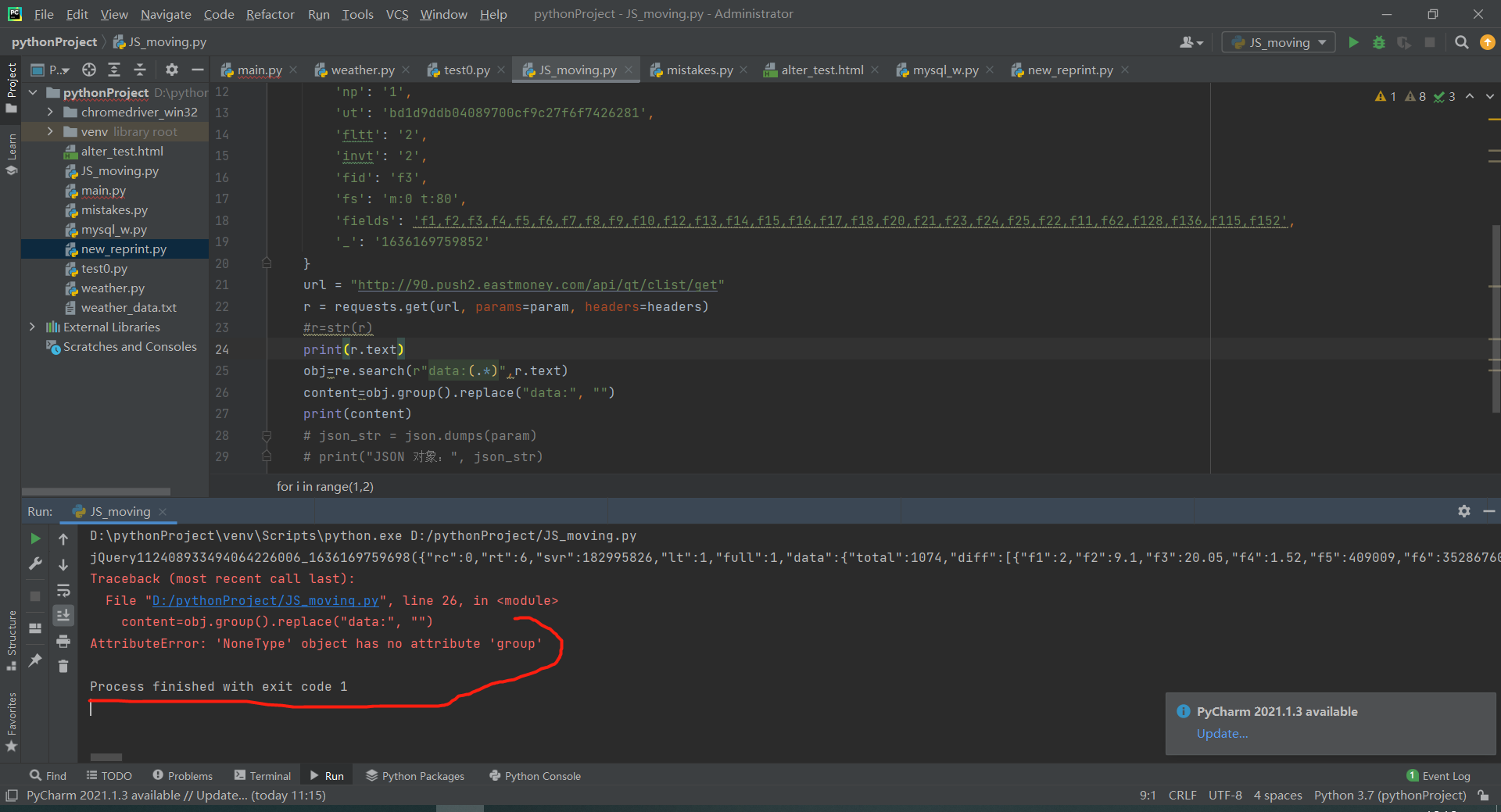
-
@mango 应该是怎么样的?但是我照着的别人视频一样的代码就能出来结果
-
@96Jennifer 返回的原始数据不就是JSON格式的吗?直接
json.loads就可以了import json import pprint import requests headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,2): param = { # 'cb': 'jQuery112408933494064226006_1636169759698', 'pn': f'{i}', 'pz': '20', 'po': '1', 'np': '1', 'ut': 'bd1d9ddb04089700cf9c27f6f7426281', 'fltt': '2', 'invt': '2', 'fid': 'f3', 'fs': 'm:0 t:80', 'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://90.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) pprint.pprint(json.loads(r.text)) -
@96Jennifer 返回的原始数据不就是JSON格式的吗?直接
json.loads就可以了import json import pprint import requests headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,2): param = { # 'cb': 'jQuery112408933494064226006_1636169759698', 'pn': f'{i}', 'pz': '20', 'po': '1', 'np': '1', 'ut': 'bd1d9ddb04089700cf9c27f6f7426281', 'fltt': '2', 'invt': '2', 'fid': 'f3', 'fs': 'm:0 t:80', 'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://90.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) pprint.pprint(json.loads(r.text))@k1995 你真聪明,非常感谢

-
找到了动态网页的内容,如何提取json字典表里面所需的内容?
import re import json import requests headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,2): param = { 'cb': 'jQuery112408933494064226006_1636169759698', 'pn': f'{i}', 'pz': '20', 'po': '1', 'np': '1', 'ut': 'bd1d9ddb04089700cf9c27f6f7426281', 'fltt': '2', 'invt': '2', 'fid': 'f3', 'fs': 'm:0 t:80', 'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://90.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) #r=str(r) print(r.text) obj=re.search(r"data:(.*)",r.text) content=obj.group().replace("data:", "") print(content) # json_str = json.dumps(param) # print("JSON 对象:", json_str)代码报错说TypeError
跟着别人视频写的代码,人家都没报错,不知道我这是哪里出毛病了?@96jennifer 加入索菲亚[勾引]
跟我一起赢战2022[加油]索菲亚家居股份有限公司是一家主要从事定制柜、橱柜、 木门、地板、配套五金、家具家品、定制大宗业务的研发、生产和销售的公司。
公司于2011年在深交所成功上市,是行业内首家A股上市公司(股票代码:002572),目前已建立起覆盖全市场的完善品牌矩阵,分别是:以中高端市场为目标的“索菲亚--柜类定制专家”,以高精人群为目标的“司米--定制家居”和“华鹤--定制家居”,以大众市场为目标的“米兰纳--定制家居”,四大品牌互相呼应,覆盖衣橱门全品类,同时辅以墙板定制、家具家品风格搭配,全面服务线上线下零售、整装、工程等全渠道客户。公司福利:
1、工作时间:双休,8小时/天;
2、五险一金,部分工种另购买相关商业意外保险;
3、享受法定公众节假日、婚假、产假、丧假、年假等相关带薪假期;
4、文体活动:年度体育文化节、年度旅游、部门活动、年会;
5、广州天河营销中心总部每周篮球、羽毛球包场活动;
6、每逢佳节,派发礼品;举办员工生日会,发放生日贺卡及生日礼品;
7、公司增城总部环境优美,丰富的娱乐设施,空调宿舍、热水器;提供三餐。
8、索菲亚培训学院,完善的培训体系。
注:员工均可享受公司的各项福利,不同的办公区域、工种及职务享受福利会适当差别。现诚聘项目经理,C#开发工程师,BI开发工程师
地点:广州市增城区,索菲亚大厦