怎么解决pycharm爬取天气预报存入mysql总是重复存入数据?
-
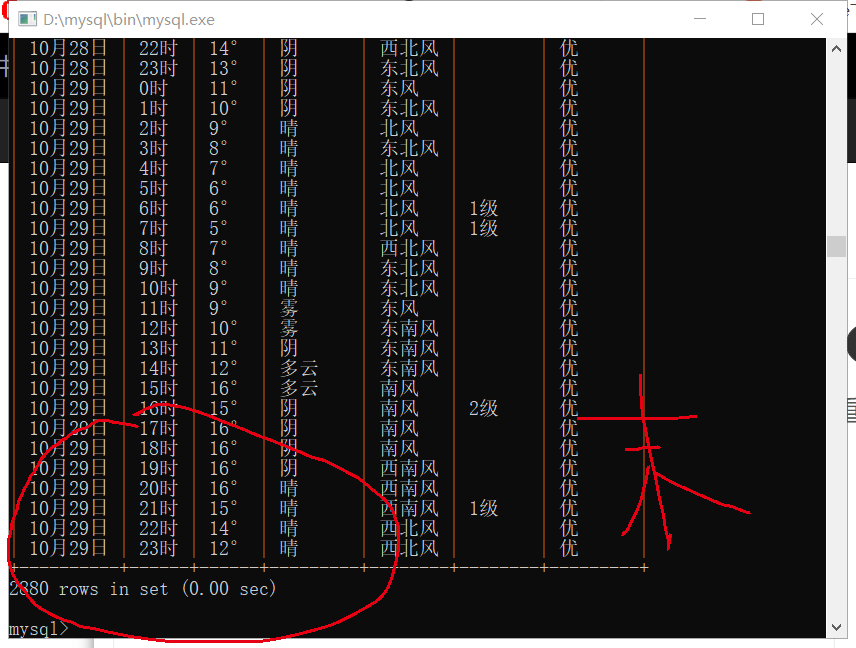
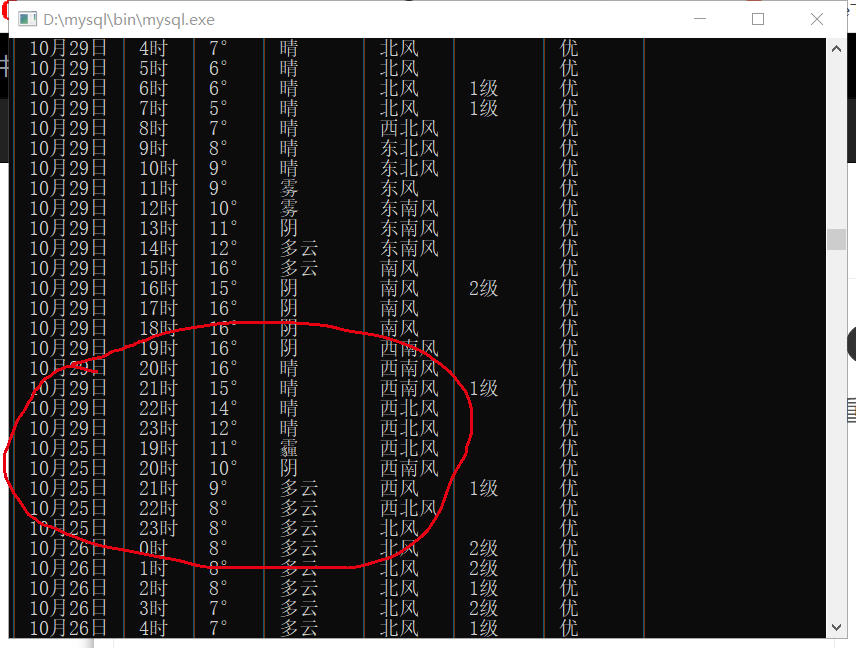
29日是爬取的最后一天数据,存完了还是从爬取当天25日又存了两遍同样的数据,这是怎么回事呀?
能不能从pycharm中写代码抑制它存入2遍或者多遍呀?后面附了代码,(还有有没有大神能教一个简单实用的不间断爬取的函数呀import time然后定义一个函数def round_time():...这种import re import time import requests import pymysql from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.chrome.service import Service import datetime conn = pymysql.connect(host='localhost', user='root', passwd='789456', db='test', port=3306, charset='utf8') cursor=conn.cursor() url = 'https://tianqi.2345.com/' html = requests.get(url).text Pattern = re.compile('{"temp":(.*?)}') datas = re.findall(Pattern, html) # fd = open('weather_data.txt', 'w', encoding='utf8') # fd.write('日期,时间,温度,天气,风向,风级,空气质量\n') url = 'https://tianqi.2345.com/' service=Service('C:\Program Files\Google\Chrome\Application\chromedriver_win32\chromedriver.exe') browser=webdriver.Chrome(service=service) browser.get(url) soup=BeautifulSoup(browser.page_source,'lxml') data_quality=soup.find('div','banner-right-canvas-kq-i clearfix').find_all('i') print('列表信息') print(data_quality) for num in data_quality: quality=num.get_text() for line in datas: data = '"temp":' + line.encode('utf-8').decode('unicode_escape') tmp = re.findall('"temp":"(.*?)"', data) weather = re.findall('"weather":"(.*?)"', data) day = re.findall('"day":"(.*?)"', data) tm = re.findall('"time_origin_text":"(.*?)"', data) wind_direction = re.findall('"wind_direction":"(.*?)"', data) wind_level = re.findall('"wind_level":"(.*?)"', data) print(day[0], tm[0], tmp[0] + '°', weather[0], wind_direction[0], wind_level[0], quality[0]) # fd.write('{},{},{},{},{},{}\n'.format(day[0], time[0], tmp[0]+'°', weather[0], wind_direction[0], wind_level[0])) # fd.close() sql = "INSERT INTO mytable(day,tm,temp,weather,wind,wscale,quality) VALUES ('%s','%s','%s','%s','%s','%s','%s')" % ( day[0], tm[0], tmp[0] + '°', weather[0], wind_direction[0], wind_level[0], quality[0]) #cursor.execute(sql) cursor.execute(sql) conn.commit() conn.close() -
没细看代码,优化的地方很多,这里就不修改你原有的代码,直接说解决方案。
如果只是去重很简单,给day和tm设置唯一联合唯一索引ALTER TABLE `mytable` ADD UNIQUE( `day`, `tm`);然后改下插入语句,加上
IGNORE关键字sql = "INSERT IGNORE INTO mytable(day,tm,temp,weather,wind,wscale,quality) VALUES ('%s','%s','%s','%s','%s','%s','%s')" % ( day[0], tm[0], tmp[0] + '°', weather[0], wind_direction[0], wind_level[0], quality[0])即已存在相同索引记录,不会报错,不更新原有记录
-
你代码写的太复杂了,完全不需要
selenium,数据别人其实都结构化好了,在var weather_data = { ... }这个变量里面。
下面代码是我解析数据的例子
import json import requests import re # 获取 HTML rsp = requests.get("https://tianqi.2345.com/") rsp.raise_for_status() # 正则匹配weather_data变量,获取结构化后数据 matched = re.search(r"daily:(.*)", rsp.text) data = matched.group().replace("daily:", "") # 解析JSON data = json.loads(data) for item in data: if 'hourly' in item: print("--------------------------") for i in item['hourly']: print(i['day'], i['time_origin_text'], i['aqi_info'], i['weather'])输出采集结果
-------------------------- 10月26日 0时 良 中雨 10月26日 1时 良 小雨 10月26日 2时 良 小雨 10月26日 3时 良 小雨 10月26日 4时 良 小雨 10月26日 5时 良 小雨 10月26日 6时 优 小雨 10月26日 7时 优 小雨 10月26日 8时 优 小雨 10月26日 9时 优 小雨 10月26日 10时 优 小雨 10月26日 11时 优 小雨 10月26日 12时 优 小雨 10月26日 13时 优 小雨 10月26日 14时 优 小雨 10月26日 15时 优 小雨 .... -
你代码写的太复杂了,完全不需要
selenium,数据别人其实都结构化好了,在var weather_data = { ... }这个变量里面。
下面代码是我解析数据的例子
import json import requests import re # 获取 HTML rsp = requests.get("https://tianqi.2345.com/") rsp.raise_for_status() # 正则匹配weather_data变量,获取结构化后数据 matched = re.search(r"daily:(.*)", rsp.text) data = matched.group().replace("daily:", "") # 解析JSON data = json.loads(data) for item in data: if 'hourly' in item: print("--------------------------") for i in item['hourly']: print(i['day'], i['time_origin_text'], i['aqi_info'], i['weather'])输出采集结果
-------------------------- 10月26日 0时 良 中雨 10月26日 1时 良 小雨 10月26日 2时 良 小雨 10月26日 3时 良 小雨 10月26日 4时 良 小雨 10月26日 5时 良 小雨 10月26日 6时 优 小雨 10月26日 7时 优 小雨 10月26日 8时 优 小雨 10月26日 9时 优 小雨 10月26日 10时 优 小雨 10月26日 11时 优 小雨 10月26日 12时 优 小雨 10月26日 13时 优 小雨 10月26日 14时 优 小雨 10月26日 15时 优 小雨 ....@k1995 写selenium是因为我不会爬取那个空气质量,是动态网页不会爬
-
没细看代码,优化的地方很多,这里就不修改你原有的代码,直接说解决方案。
如果只是去重很简单,给day和tm设置唯一联合唯一索引ALTER TABLE `mytable` ADD UNIQUE( `day`, `tm`);然后改下插入语句,加上
IGNORE关键字sql = "INSERT IGNORE INTO mytable(day,tm,temp,weather,wind,wscale,quality) VALUES ('%s','%s','%s','%s','%s','%s','%s')" % ( day[0], tm[0], tmp[0] + '°', weather[0], wind_direction[0], wind_level[0], quality[0])即已存在相同索引记录,不会报错,不更新原有记录
-
@k1995 上面那个alter 在mysql里面报错
-
你代码写的太复杂了,完全不需要
selenium,数据别人其实都结构化好了,在var weather_data = { ... }这个变量里面。
下面代码是我解析数据的例子
import json import requests import re # 获取 HTML rsp = requests.get("https://tianqi.2345.com/") rsp.raise_for_status() # 正则匹配weather_data变量,获取结构化后数据 matched = re.search(r"daily:(.*)", rsp.text) data = matched.group().replace("daily:", "") # 解析JSON data = json.loads(data) for item in data: if 'hourly' in item: print("--------------------------") for i in item['hourly']: print(i['day'], i['time_origin_text'], i['aqi_info'], i['weather'])输出采集结果
-------------------------- 10月26日 0时 良 中雨 10月26日 1时 良 小雨 10月26日 2时 良 小雨 10月26日 3时 良 小雨 10月26日 4时 良 小雨 10月26日 5时 良 小雨 10月26日 6时 优 小雨 10月26日 7时 优 小雨 10月26日 8时 优 小雨 10月26日 9时 优 小雨 10月26日 10时 优 小雨 10月26日 11时 优 小雨 10月26日 12时 优 小雨 10月26日 13时 优 小雨 10月26日 14时 优 小雨 10月26日 15时 优 小雨 .... -
@k1995 mysql会显示duplicate entry
还有一个问题请问这代码怎么设置一个简hui单的每天某一时间爬取呀,或者不停爬,不用手点击
-
@k1995 好的,谢谢
