想问问各位怎么保持自己爬虫实例一直不退,而且还一直进步的?你们都是做的github上的实战项目吗?可以分享给我一些经验和好的实战项目吗?非常感谢
96Jennifer
@96Jennifer
-
各位大佬都是做的哪里的python爬虫实例呀? -
定时爬取天气到mysql程序不报错,但是也爬不出来东西
import requests import pymysql import datetime import re import pandas as pd import time from pypinyin import lazy_pinyin from bs4 import BeautifulSoup def run(): db = pymysql.connect(host='localhost', user='root', password='789456', db='test', charset='utf8mb4') cursor = db.cursor() sql_insert = 'INSERT INTO new_d(date, city, temp,low,top, quality, wind) ' \ 'VALUES (%s, %s,%s, %s, %s, %s, %s)' #读取需要爬取的城市名单 city = pd.read_excel('D:\city.xls')['城市'] late_url = ['/15'] for j in range(0, len(city)): try: # 将城市的中文转换成拼音 word = ''.join(lazy_pinyin(city[j])) print('正在查询%s的天气预报' % str(city[j])) base_url = 'https://www.tianqi.com/' # 拼接三段形成url url = base_url + word + late_url headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} response = requests.get(url, headers=headers).text # 用BeautifulSoup解析网页 soup = BeautifulSoup(response, 'lxml') # 定位未来15天天气的数据 future_list = str(soup.find_all("div", {"class": "box_day"})) # 正则匹配时间 date_list = re.findall(r'<h3><b>(.*?)</b>', future_list) temp_list = re.findall(r'<li class="temp">(.*?)</b>', future_list) quality_list = re.findall(r'空气质量:(.*?)">', future_list) wind_list = re.findall(r'<li>(.*?)</li>', future_list) print(quality_list) for n in range(0, len(date_list)): date = date_list[n] temp = temp_list[n] quality = quality_list[n] wind = wind_list[n] fir_temp_list = temp.split(' ')[0] sec_weather_list = temp.split(' ')[1] # print(sec_weather_list) new_list = sec_weather_list.split('~<b>') low = new_list[0] top = new_list[1] print(date, fir_temp_list, low, top, quality, wind) # print(temp.split(' ~ ')[1]) # print(city[j], today[0], weather, low_temp, top_temp, real_shidu, fengxiang[0], ziwaixian[0]) cursor.execute(sql_insert, (date, city[j], fir_temp_list, low, top, quality, wind)) db.commit() time.sleep(1) except: pass db.close() if __name__ == '__main__': #通过每隔20秒检测一遍是否到达时间 while 1: now_h = datetime.datetime.now().hour now_m = datetime.datetime.now().minute if now_h == 9 and now_m == 30: run() else: time.sleep(2)
这下面是城市名的爬取
import requests from bs4 import BeautifulSoup url = "https://www.tianqi.com/chinacity.html" header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"} res = requests.get(url=url, headers=header) html = res.text.encode('iso-8859-1') soup = BeautifulSoup(html, "html.parser", from_encoding="utf-8") # 获取所以的a city = soup.find('div', class_="citybox") a = city.find_all('a') f = open('city.txt', 'w', encoding='utf-8') for di in a: text = di.get_text() print(text) f.write(text + '\n') -
如何读取json格式的内容,报错TypeError@k1995 你真聪明,非常感谢

-
如何读取json格式的内容,报错TypeError@mango 应该是怎么样的?但是我照着的别人视频一样的代码就能出来结果
-
如何读取json格式的内容,报错TypeError找到了动态网页的内容,如何提取json字典表里面所需的内容?
import re import json import requests headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,2): param = { 'cb': 'jQuery112408933494064226006_1636169759698', 'pn': f'{i}', 'pz': '20', 'po': '1', 'np': '1', 'ut': 'bd1d9ddb04089700cf9c27f6f7426281', 'fltt': '2', 'invt': '2', 'fid': 'f3', 'fs': 'm:0 t:80', 'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://90.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) #r=str(r) print(r.text) obj=re.search(r"data:(.*)",r.text) content=obj.group().replace("data:", "") print(content) # json_str = json.dumps(param) # print("JSON 对象:", json_str)代码报错说TypeError
跟着别人视频写的代码,人家都没报错,不知道我这是哪里出毛病了?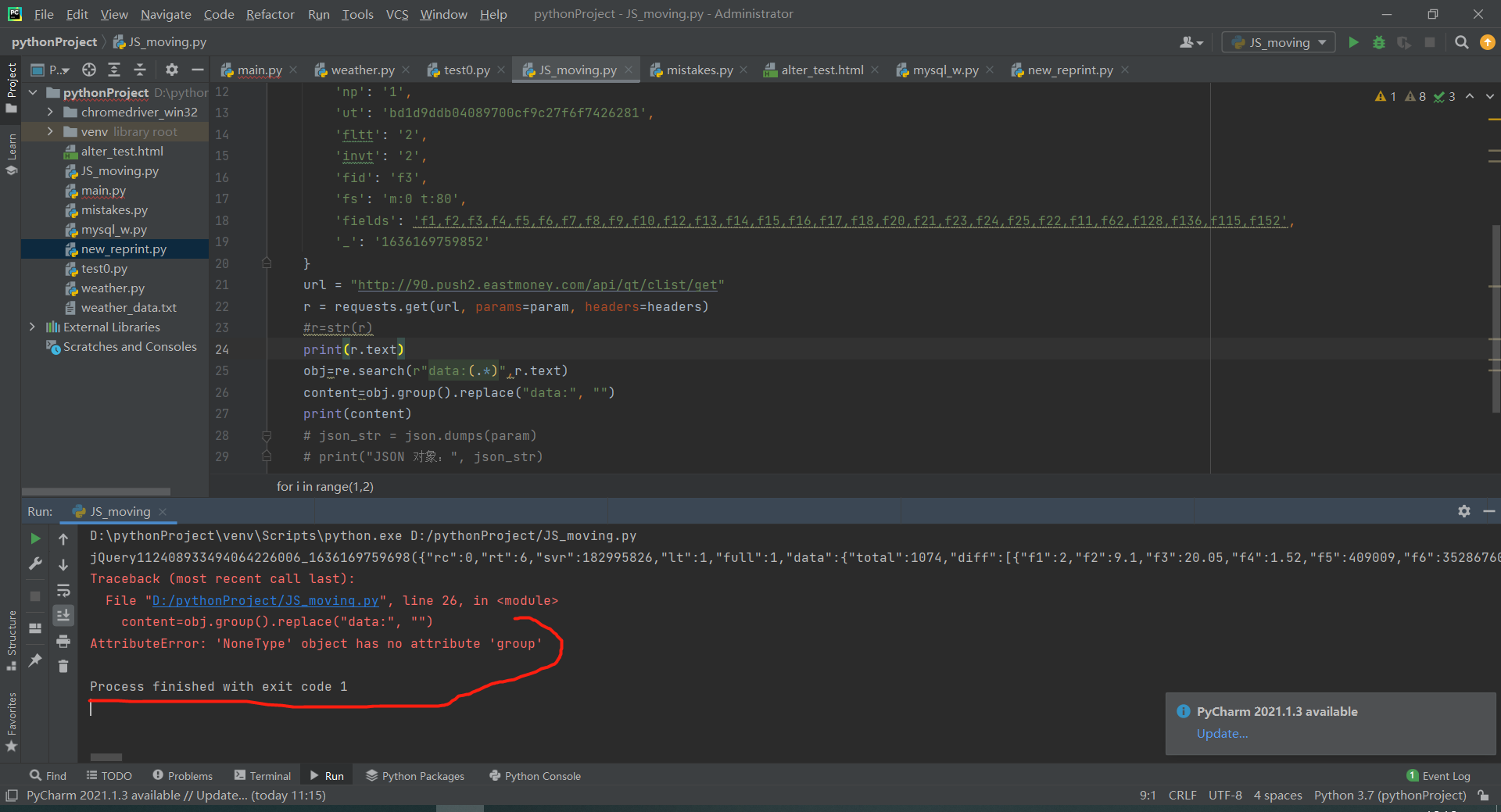
-
如何MATLAB中输入这种积分公式?
谢谢各位 -
关于动态爬取json格式文件@96jennifer 原因找到了
因为param中批量加入引号,引号与内容有空格,
更新代码import requests headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,55): param = { 'cb': 'jQuery112408933494064226006_1636169759698', 'pn': f'{i}', 'pz': '20', 'po': '1', 'np': '1', 'ut': 'bd1d9ddb04089700cf9c27f6f7426281', 'fltt': '2', 'invt': '2', 'fid': 'f3', 'fs': 'm:0 t:80', 'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://90.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) print(r.text) -
怎么解决pycharm爬取天气预报存入mysql总是重复存入数据?@k1995 好的,谢谢
-
关于动态爬取json格式文件请问朋友们知道为什么打印text显示jQuery,里面的data为null?
我跟着视频做的博主data里面都是字典表内容,这个是我的import requests headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} for i in range(1,2): param = { 'cb': ' jQuery112408933494064226006_1636169759698', 'pn': f' {i}', 'pz': ' 20', 'po': ' 1', 'np': ' 1', 'ut': ' bd1d9ddb04089700cf9c27f6f7426281', 'fltt': ' 2', 'invt': ' 2', 'fid': ' f3', 'fs': ' m:0 t:80', 'fields': ' f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152', '_': '1636169759852' } url = "http://49.push2.eastmoney.com/api/qt/clist/get" r = requests.get(url, params=param, headers=headers) print(r.text)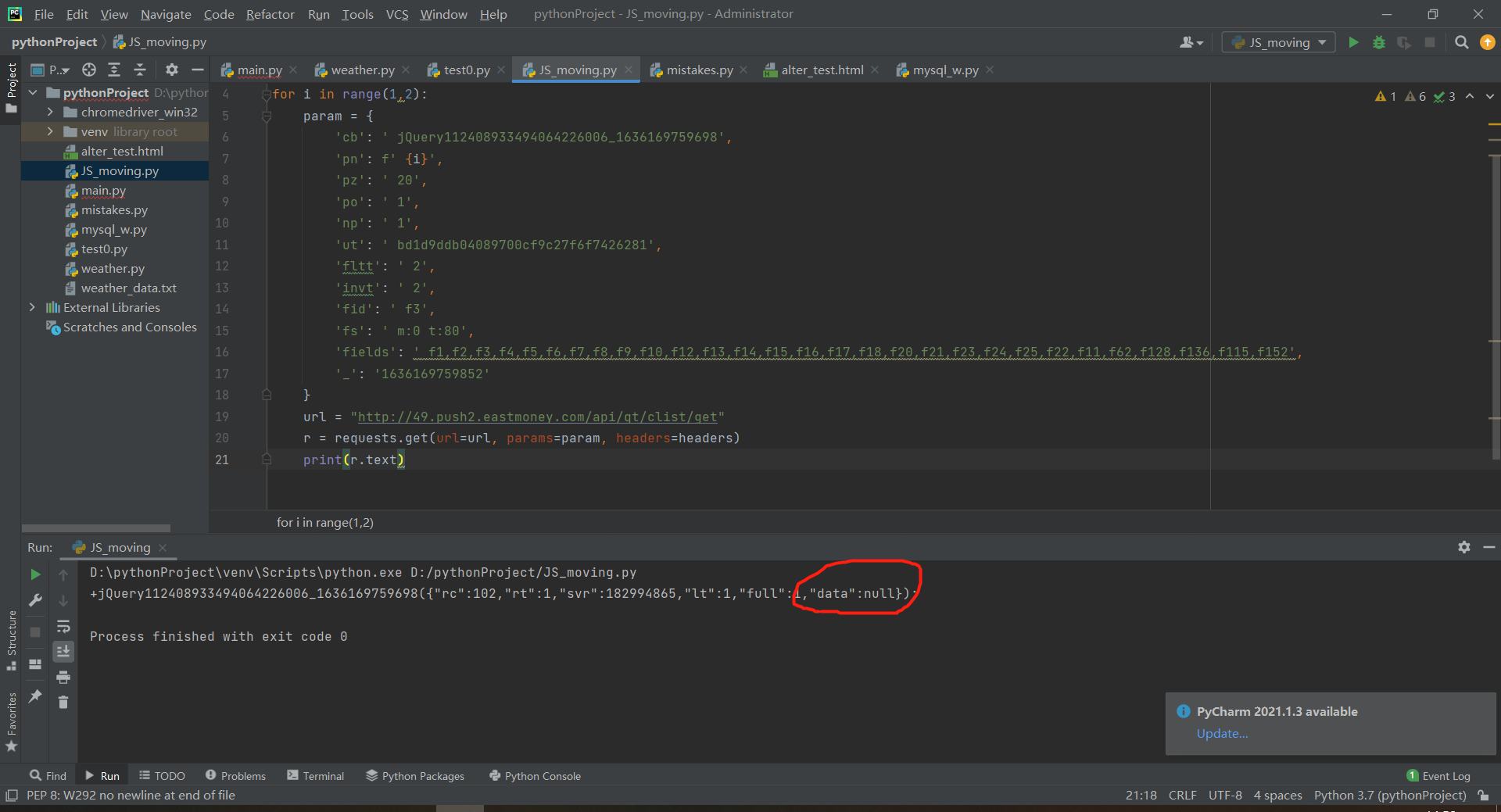
不知道哪里有问题?求解答。网址为“东方财富网” -
怎么解决pycharm爬取天气预报存入mysql总是重复存入数据?@k1995 mysql会显示duplicate entry
还有一个问题请问这代码怎么设置一个简hui单的每天某一时间爬取呀,或者不停爬,不用手点击
-
怎么解决pycharm爬取天气预报存入mysql总是重复存入数据?@k1995 上面那个alter 在mysql里面报错
-
怎么解决pycharm爬取天气预报存入mysql总是重复存入数据?@k1995 写selenium是因为我不会爬取那个空气质量,是动态网页不会爬
-
这论坛怎么看自己的问题呀不知道我的问题有没有人回复
-
怎么解决pycharm爬取天气预报存入mysql总是重复存入数据?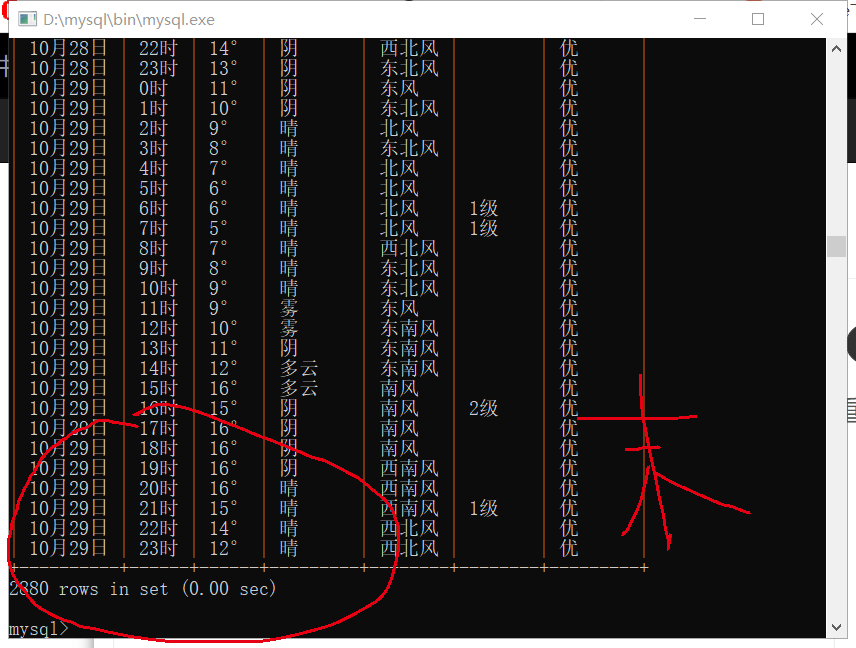
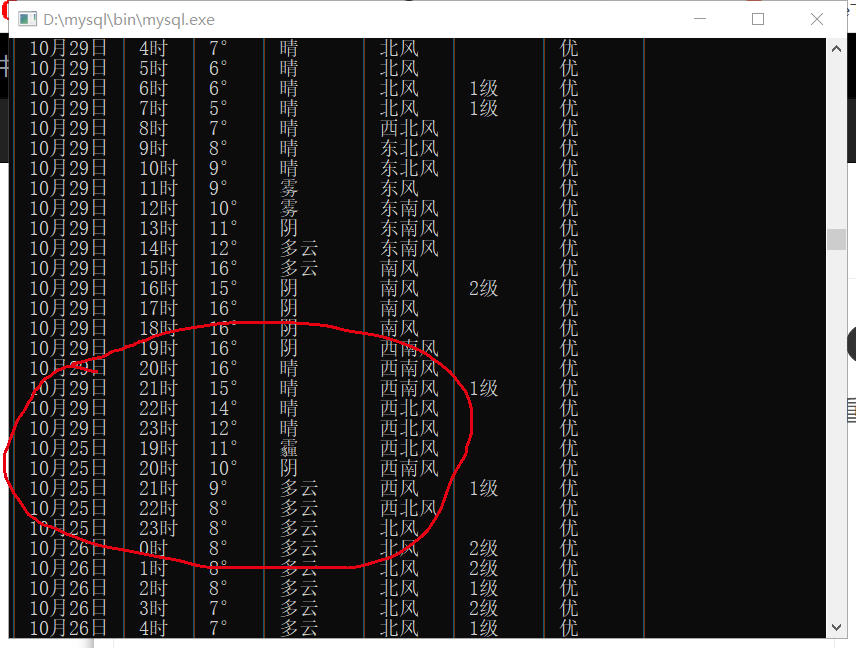
29日是爬取的最后一天数据,存完了还是从爬取当天25日又存了两遍同样的数据,这是怎么回事呀?
能不能从pycharm中写代码抑制它存入2遍或者多遍呀?后面附了代码,(还有有没有大神能教一个简单实用的不间断爬取的函数呀import time然后定义一个函数def round_time():...这种import re import time import requests import pymysql from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.chrome.service import Service import datetime conn = pymysql.connect(host='localhost', user='root', passwd='789456', db='test', port=3306, charset='utf8') cursor=conn.cursor() url = 'https://tianqi.2345.com/' html = requests.get(url).text Pattern = re.compile('{"temp":(.*?)}') datas = re.findall(Pattern, html) # fd = open('weather_data.txt', 'w', encoding='utf8') # fd.write('日期,时间,温度,天气,风向,风级,空气质量\n') url = 'https://tianqi.2345.com/' service=Service('C:\Program Files\Google\Chrome\Application\chromedriver_win32\chromedriver.exe') browser=webdriver.Chrome(service=service) browser.get(url) soup=BeautifulSoup(browser.page_source,'lxml') data_quality=soup.find('div','banner-right-canvas-kq-i clearfix').find_all('i') print('列表信息') print(data_quality) for num in data_quality: quality=num.get_text() for line in datas: data = '"temp":' + line.encode('utf-8').decode('unicode_escape') tmp = re.findall('"temp":"(.*?)"', data) weather = re.findall('"weather":"(.*?)"', data) day = re.findall('"day":"(.*?)"', data) tm = re.findall('"time_origin_text":"(.*?)"', data) wind_direction = re.findall('"wind_direction":"(.*?)"', data) wind_level = re.findall('"wind_level":"(.*?)"', data) print(day[0], tm[0], tmp[0] + '°', weather[0], wind_direction[0], wind_level[0], quality[0]) # fd.write('{},{},{},{},{},{}\n'.format(day[0], time[0], tmp[0]+'°', weather[0], wind_direction[0], wind_level[0])) # fd.close() sql = "INSERT INTO mytable(day,tm,temp,weather,wind,wscale,quality) VALUES ('%s','%s','%s','%s','%s','%s','%s')" % ( day[0], tm[0], tmp[0] + '°', weather[0], wind_direction[0], wind_level[0], quality[0]) #cursor.execute(sql) cursor.execute(sql) conn.commit() conn.close()